Understanding diverse interests in the commons
An important component of effective community-building and co-design is to understand the interests at the table.
Here we provide a brief introduction to some ways of thinking about data reuse interests that might be useful to help a community understand perspectives.
Having the right conversations at the right level
At this point it is useful to introduce a rough schema of the kinds of interest in data integration and reuse. This will be used for the remainder of the document to understand various roles and considerations in actually doing the work.
The chart below is an example of the different ways of cutting the cake and organising the conversations, based on the types of interest of the participants.
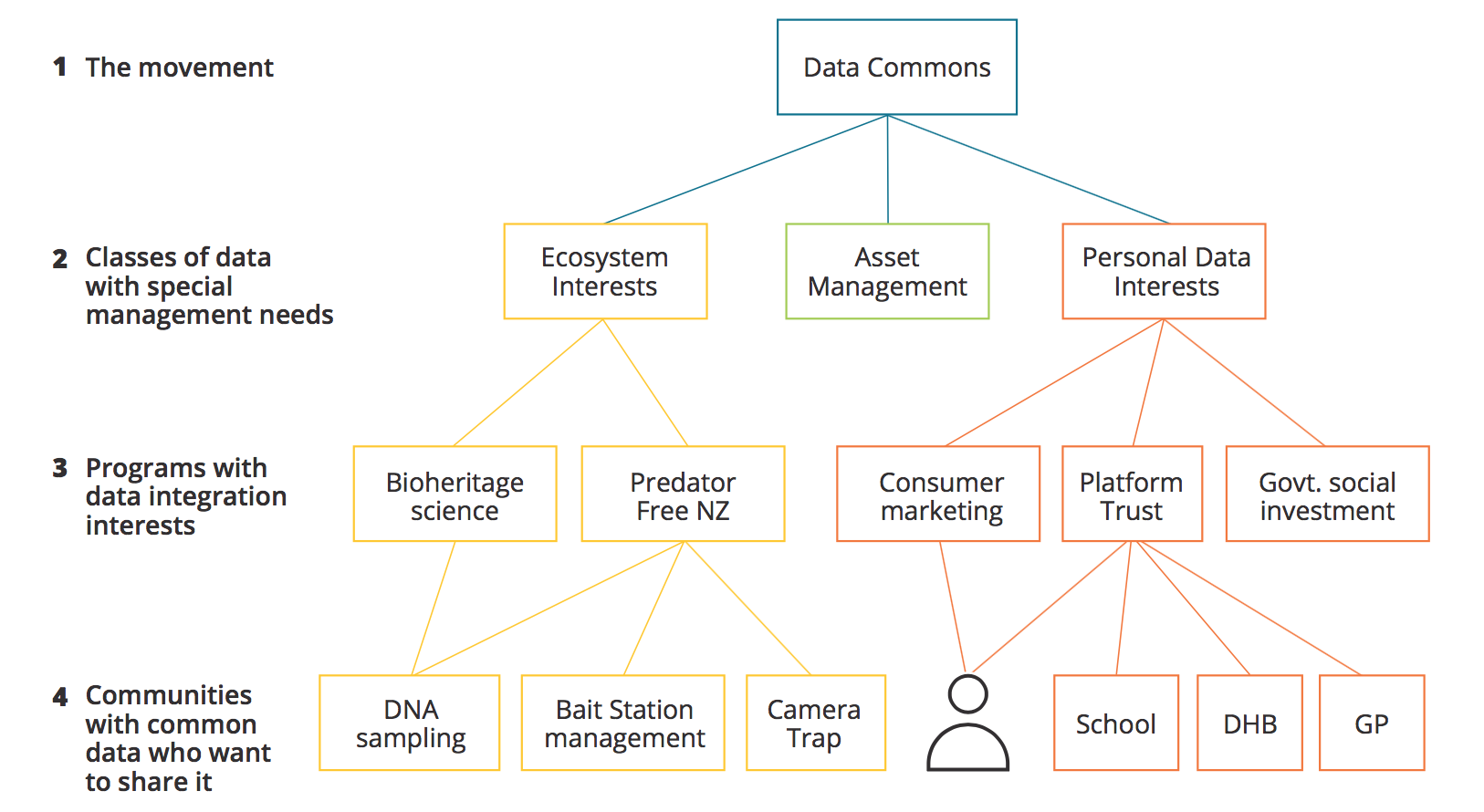
The overall movement (I) is concerned with supporting the commons as a generalised solution for how to integrate and reuse all data. This paper is interested in this level of question. Below this, there are subgroups with interests in classes of data (II): clarity in this area is necessary to contain the scope and size of the discussion about how to handle particular classes of data. Wellington City Council’s interest was in asset data integration and didn’t have much to say about predator-free NZ or personal data. Programme interests (III) have a particular integration and reuse challenge in mind that they want to solve, and typically a well-formed community of such interests (where relationships have been established). Data Interests (IV) are siloed interests in particular datasets: people who are sharing that data within their community but not thinking about integrating it with other kinds of dataset or reuse for purposes outside of those it was collected for.
With these levels of interest in mind, we consider the work that needs to be done to coordinate them to start up and sustain a commons-based approachto data sharing. This is defined in more detail below.
The Data Commons movement. There is a movement of people interested in building a commons-based approach to data integration and reuse. They have a top-down interest in helping build the relationships, high-level design principles, and institutional frameworks appropriate for all specific instances of the Commons. At the level of the whole commons community, there will need to be some top-down protocol-setting, including answers to some of the big questions such as “right to forget”. The Commons community as a whole is also likely to have a big say in the general provisions for transactions and sharing. They will have a third role too: ratifying bottom-up standards from data experts to ensure they are generalisable across the commons.
Data class interests. There are several large classes of data that have characteristic properties in terms of the way that data can be used or integrated. These include data about people (personal data); assets and the built environment (roads, pipes, buildings, networks – increasingly including the Internet of things, i.e. where people interact with the built environment); the economy (production, incomes, employment, tax, finance, etc.); and the biosphere (the natural environment, its organisms, and their movement). These definitions allow us to limit the scope of the conversation based on how these subcommunities of data interest identify themselves. But data classes are merely pragmatic subgroupings. They break down, for example, with social housing, which is the intersection of asset data and personal data. Then you have to start another conversation.
Integration programme interests.
Communities of Interest are particular communities of people who may have a common interest in solving an integration and reuse challenge for that community’s own purposes; or entrepreneurs with a particular data reuse idea that they wish to build. Examples include Manaiakalani Trust (education achievement), the Platform Trust (better coordination and collaborative delivery of community mental health), Predator Free NZ (sharing data among scientists, trappers, and volunteers engaged in a mission to eradicate predators from the New Zealand ecosystem).Typically, such activity would begin without reference to a commons-based approach, leading to a point solution that is hard to scale or build upon. However, if they were to climb aboard the Data Commons, they would find a ready-made broader community allowing high-trust data reuse transactions and a potentially lower-cost solution with access to a wider range of data of interest. Connecting these Communities of Interest – which have a natural incentive to share information – to the Data Commons movement can help them scale and efficiently manage their integration challenge in a high-trust way for their constituents.
In common data interests.
Within existing data silos, there are communities of common interest in a specific kind of data, who use it for the purpose for which it was co-produced – not necessarily repurposing it. At this level – which is where a lot of data sharing opportunities and challenges first emerge – we are primarily concerned with the potential for sharing data with people and organisations that have common interests and shared values. They are best placed to develop at least the technical protocols and standards for data capture, storage, and integration. Because they are more familiar than anyone else with their particular kind of data and its typical uses, they best understand the sensitivities and risks around reuse.Medical professionals, for example, are interested in medical records and have developed taxonomies (ICD10 codes, Read Codes) to allow that data to be transferred and interpreted easily among that community. Scientists are developing metadata standards for the management, sharing, and integration of DNA data obtained from soil and stream samples. Predator Free NZ will need to develop metadata standards and taxonomies for bait stations and camera traps data. There may be a low level of interest in repurposing or reusing. However, if data integration interests (I–III) wish to use this data, then they need to engage with the In Common Data Interest Groups (IV). These groups have a key role in developing the lower-level data standards (the bottom-up protocols) that allow their data to be used and interpreted by non-specialist interests – so connecting them to people with data integration interests is important.
The work of building and maintaining the commons protocols, according to the role of the interest group, is depicted below using an example applied to personal data.
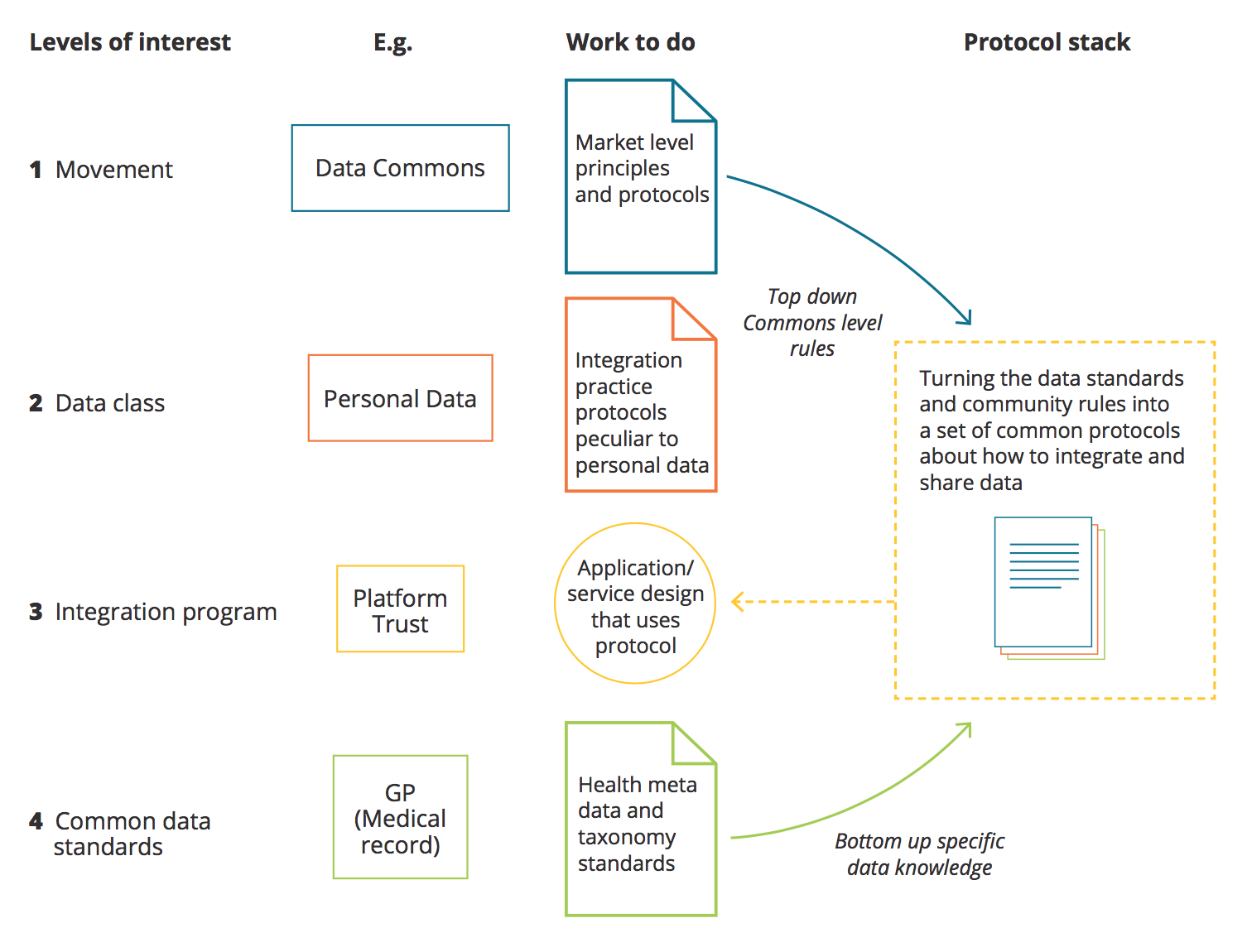
This schema is useful for considering some of the (relationship and community-building) reasons why the status quo seems to be stuck at low-level data sharing. As already noted, most data in New Zealand is trapped in organisations operating at level IV – people, banks, government agencies that find it too costly, risky, or relatively low-value to engage in data sharing or integration any more widely than their immediate community of common interests. Or they have leapt to point solutions at level III and find them hard to scale – since no work of developing standards and more general protocols was done. The StatsNZ IDI point solution and the Social Investment Unit’s and MSD’s coercive practices make those solutions hard to manage or scale. The same is true in the private sector. It is difficult for business-to-business data integration solutions not to get bound up in red tape because they are largely extractive point solutions that have not been set up in conversation with other interests (such as the shoppers themselves). If the solutions are aimed at owning and monetising data, they will be designed specifically to limit rival access – and so data remains fragmented and only of limited general value.